Real-time Machine Learning Competition on Data Streams
A Track in the IEEE Big Data 2019 Big Data Cup
Description of the Tasks
- This track in the IEEE Big Data 2019 Big Data Cup represents Machine Learning competition on data streams the first of its kind. The main idea is to build incremental classifiers and provide the predictions for the data instances that are arriving in stream.
- In order to organize this kind of competition there was a need for a dedicated platform with specific infrastructure. Having this in mind, this competition will be conducted on our novel platform built for those purposes. The Platform For Data Science Competitions on Data Streams is able to provide multiple streams to multiple users, to receive multiple streams, process them and provide the leader board and live results. The link to our platform will be provided as soon as all the preparations have been finished.
- Processing data streams is in high demand in recent years due to the
rapid development of IoT and many other technologies that act as data sources. Data are
generated in real-time from a high number of various data sources: sensors, IoT devices,
social networks, applications, bank and market transactions. Building prediction models for
data streams is an essential task due to its importance in real-time decision making
process. However, this is very challenging because of the dynamic nature of the data where
instances arrive in high speed and the stream is often subject to changes. The competition
that we are proposing represents the typical scenario in Data Stream Mining that has
different requirements compared to the traditional batch learning setting.
The most significant ones are :
- Requirement 1 Process an example at a time and inspect it only once at most.
- Requirement 2 Use a limited amount of memory.
- Requirement 3 Work in a limited amount of time.
- Requirement 4 Be ready to predict at any time.
-
The figure 1 shows how the data stream occurs in Data Stream Mining process. In this setting, data are
not available as static dataset, though data arrive in stream of records (instances).
We assume that records in the data stream arrive in batches (batch can also have size of one
record). We distinguish two types of batches:
- Initial batch: is used to build and train the initial model. It is used to avoid the cold start problem and as such contains training instances only, providing both features and true value of targets. Initial batch is usually larger than regular batches.
- Regular batch: provides new test instances and true values of previous ones. True label values are used to update models whereas test instances are used to predict future values of the target. All intermediate predictions are used to evaluate the quality of the model.
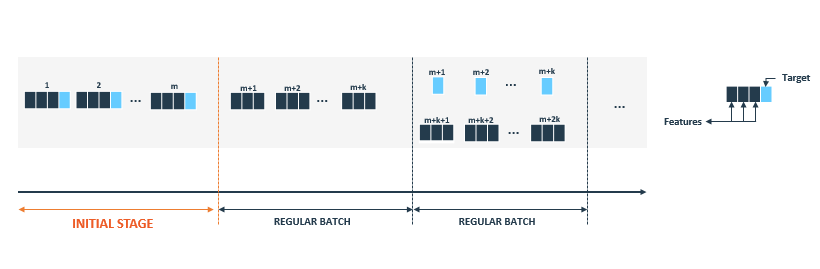
Figure 1 - Data Stream flow
- The goal of the competition is to build models able to predict the future values of the series with high accuracy while taking into account the evolutionary nature of these data. These models must be able to learn incrementally and detect changes in order to adapt to them as soon as they occur. When the competition starts, data will be released as a data stream. Their models will be evaluated using the evaluation metric, that are detailed in Submissions section, where also you can download the Starter Pack.